Что в облике тебе моем: алгоритм, предсказывающий оценочные суждения лиц
Автор: Dmytro Kikot
Источник
Встречают по одежке, а провожают по уму. Не суди книгу по ее обложке. Внешность обманчива. Все эти расхожие выражения тем или иным образом относятся к умению человека строить предположения касательно другого человека на базе исключительно внешних факторов. Встретив незнакомца, мы предполагаем его характер, статус и даже интеллектуальные способности в зависимости от внешности, по большей степени в зависимости от черт и выражения лица. В этом нет ничего предосудительного, так как это чаще всего не совсем сознательный процесс. Но есть ли в таком «гадании» по лицам логика и насколько подобные суждения соответствуют действительности? Часто предположения относительно человека оказываются неверными, но сам факт их наличия является важным социальным аспектом. Ученые из Технологического института Стивенса (США) разработали алгоритм, способный имитировать оценку человека по его лицу, чтобы понять, какие предположения о том или ином человеке будут строить незнакомцы, базируясь только на внешности. Насколько точно алгоритм предсказывает суждения человека, какие предположения были построены, и как еще можно использовать этот алгоритм? Ответы на эти вопросы мы найдем в докладе ученых. Поехали.
Основа исследования
Если посмотреть на мир дикой природы, то можно с уверенностью заявить о его многообразии. Внешние межвидовые и внутривидовые отличия играют важную роль в самых разных аспектах жизни того или иного существа (охота, поиск партнера, избегание опасностей, конкуренция за территорию и т.д.). Некоторые виды предпочитают быть незаметными, другие наоборот выставляют на показ свои самые выдающиеся детали внешности (к примеру, самцы павлинов с их невероятными хвостами-веерами). Что же касается человека, то картина особо не меняется: кто-то окрашивает волосы в яркие цвета, кто-то предпочитает одеваться во все серое и быть незаметным, кто-то вообще не думает обо всем этом. Однако, какую бы тактику человек не выбрал, один аспект всегда будет привлекать больше всего внимания — лицо. Да, увидев незнакомца с ярко-зелеными волосами, мы первым делом бросим взгляд именно на волосы, но второй (куда более долгий и более анализирующий) взгляд упадет на его лицо. И ту начинается неосознанный анализ того, кем же может быть этот экстравагантный зеленоволосый тип.
Лица являются одним из самых важных стимулов, с которыми сталкиваются люди. Первое, что визуально начинают различать младенцы, это именно лица. А обработка информации, относящейся к лицам, задействует особые процессы в головном мозге человека. Глядя на лица, мы используем определенные атрибуты, которые им приписываем, часто неосознанно: худое, уставшее, светлое, умное и т.д.
Эти атрибуты можно разделить на две условные категории: объективные и субъективные. В первом случае мы оцениваем возраст, телосложение, пол. Во втором все куда более любопытно, так как мы применяем атрибуты, которые в последствии отвечают на вопрос — можно ли доверять владельцу этого лица или нет.
Чаще, чем бы мы хотели признать, субъективные атрибуты, приписанные нами тому или иному человеку, не соответствуют действительности. Тем не менее такими неточными суждениями грешат все люди на планете, независимо от вероисповедания, национальности, ориентации и образования. Грубо говоря, судить людей по лицам (часто ошибочно) заложено в каждом из нас.
Ученые говорят, поскольку о любом лице можно судить по таким атрибутам, эти психологические параметры универсальны в том смысле, что они неявно определены в пространстве почти всех возможных лиц, контекстов и условий наблюдения. Эти факторы объединяются, чтобы сформировать разнообразный «ландшафт» стимулов, что затрудняет захват соответствующего психологического содержания во всей его полноте.
Важность анализа атрибутов лица привела к распространению методов научного моделирования лиц, которые в целом можно разделить на два подхода. Первый основан на использовании фотографий лиц, часто связанных между собой аннотациями ориентиров. Второй генерирует искусственные лица с помощью параметрических трехмерных моделей.
Фотографии обеспечивают больший реализм, но ограничены доступными наборами данных лицевых стимулов, которые служат основой для интерполяции, и самими алгоритмами интерполяции, которые часто требуют высококачественных аннотаций ориентиров, недостижимых без вмешательства человека. Искусственно созданные лица не подпадают под эти ограничения, но им не хватает разнообразия и реализма. Следовательно, ни один из подходов не дает работоспособных моделей, которые выражают все богатство и разнообразие человеческих лиц.
Если же минимизировать человеческий фактор, а именно применить машинное обучение (нейронные сети, к примеру), то можно получить систему, способную моделировать лица, используя в качестве исходных данных подборки фотографий. Это третий подход к моделированию лиц. Однако, даже при самых точных репрезентативных моделях лиц, их крайне сложно связать с тем, как эти лица воспринимались бы и оценивались бы реальными людьми. Проще говоря, как человек строит предположения относительно другого человека, судя по его лицу, это процесс, который сложно перевести в плоскость машинного мышления.
Авторы рассматриваемого нами сегодня труда, считают, что ключом к раскрытию научного потенциала этих моделей являются крупномасштабные наборы данных о человеческом поведении, недостижимые с помощью традиционных лабораторных экспериментов. В частности, такие большие наборы данных предоставляют достаточно доказательств для определения надежного сопоставления между выразительными многомерными представлениями из моделей машинного обучения и мысленными представлениями лиц человека.
Ученые количественно оценили верхнюю границу надежности картирования лиц с точки зрения надежности выводов о лежащих в основе атрибутах. Затем они определили, как эта надежность масштабируется в зависимости от количества оцениваемых лиц, количества оценок одного лица и размерности пространства признаков. Полученное сопоставление далее использовалось для прогнозирования и манипулирования восприятия произвольных лиц. Другими словами, ученые могли скорректировать фото лица так, чтобы машина построила другое суждение о нем.
Такое картирование может быть вычислено для любого психологически значимого вывода об атрибутах. В данном труде ученые сосредоточились на трех классах таких выводов.
Во-первых, есть выводы, определяемые субъективными впечатлениями относительно объективных свойств (например, возраста и комплекция). Эти более объективные свойства, которые также включают укладку волос, наличие аксессуаров (например, очков), взгляд и выражение лица, обычно изучаются в компьютерном зрении, где они называются «атрибутами» или «мягкой биометрией».
Затем следуют выводы о субъективных и социально сконструированных атрибутах, таких как надежность и мужское/женское и т.д.
Наконец, есть выводы о полностью субъективных атрибутах, таких как “знакомство”, когда наблюдатель является единственным источником истины относительно наблюдаемого лица (и его владельца).
В исследовании использовался онлайн-краудсорсинг, чтобы получить оценки атрибутивного вывода для чуть более 1000 синтетических (хотя и весьма натуралистичных) лицевых стимулов по 34 атрибутам (признакам), с оценками не менее 30 уникальных участников на пару атрибут-стимул, в общей сложности 1020000 человеческих суждений.
Результаты исследования
Структура атрибутивных выводов
Чтобы изучить структуру атрибутивных выводов, необходимо было вычислить корреляцию между средними значениями оценки лиц для каждой пары атрибутов (изображение №1).
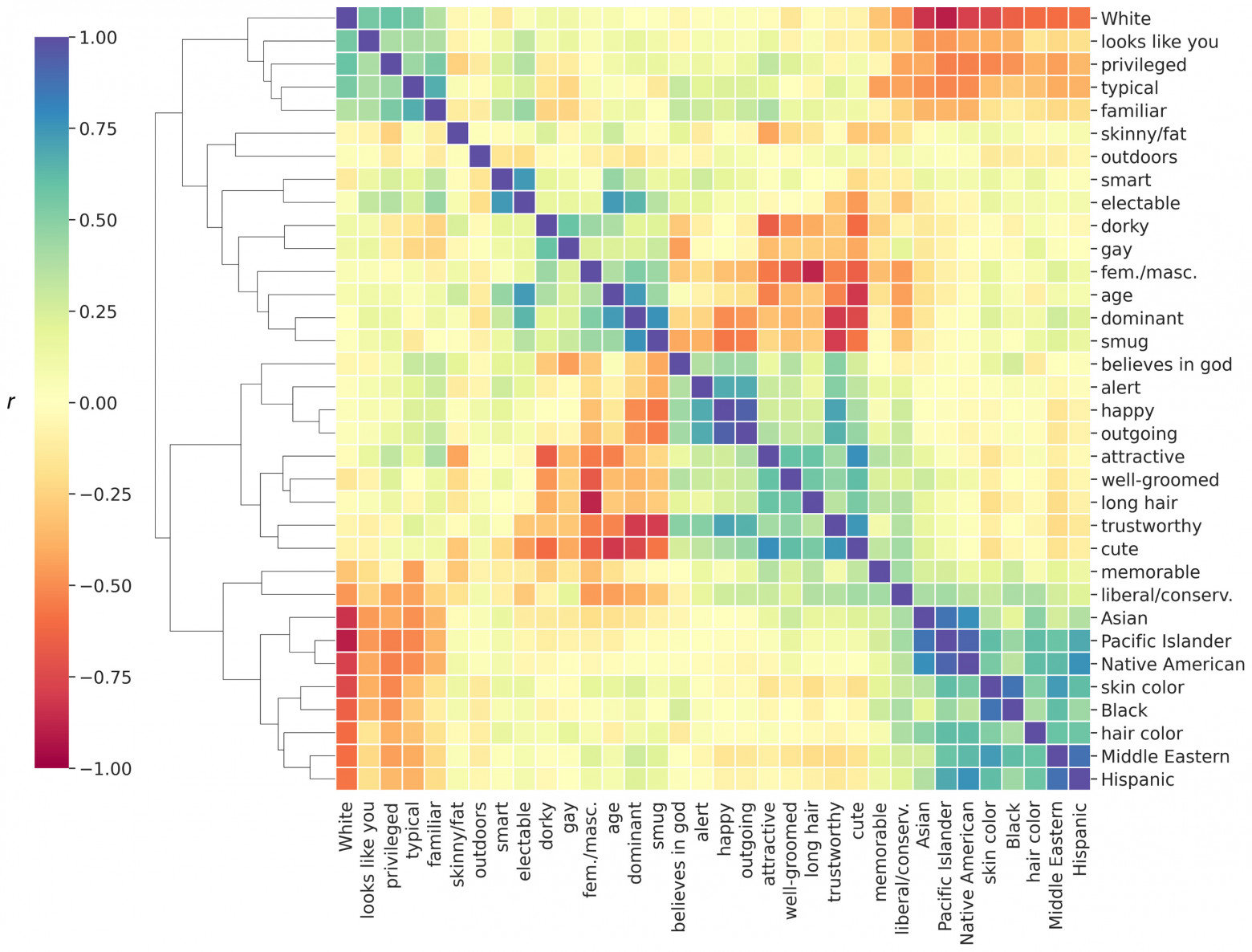
Многие атрибуты были сильно коррелированы, в том числе счастливый-общительный (r = 0.93) и доминирующий-надежный (r = -0.81). Тогда как другие в значительной степени не были связаны: умный-привлекательный (r = 0.01), умный-надежный (r = 0.02), либеральный/консервативный-верующий (r = 0.08), доверительный-привлекательный (r = 0.05).
Хотя некоторые из этих корреляций согласуются с предыдущими исследованиями, другие — нет. Во-первых, хотя предыдущая работа показала, что суждения о надежности и доминантности часто имеют отрицательную корреляцию либо корреляция очень мала (порядка -0,2), в данном исследовании корреляция (-0.81) оказалась намного сильнее. Во-вторых, ранее было обнаружено, что суждения об уме или компетентности сильно положительно коррелируют с суждениями о привлекательности и надежности (со значениями до ≈ 0.8), в то время как в этом труде были обнаружены лишь незначительные корреляции между этими выводами об атрибутах.
Одним из объяснений таких расхождений может быть то, что использованные в данном труде лицевые стимулы более разнообразны, чем в ранее проведенных работах (особенно в аспекте возраста, так как ранее не использовались детские лица). Это объяснение вполне правдоподобно, учитывая, что корреляционная структура суждений о лицах детей отличается от структуры суждений о лицах взрослых.
Чтобы проверить эту гипотезу, ученые пересчитали межатрибутные корреляции на подмножествах данных с ограниченным возрастным диапазоном. Было обнаружено, что включение детских лиц частично объясняет некоторые несоответствия (например, умный-привлекательный) и не объясняет другие (надежный-доминантный).
Также стоит отметить, что запоминающиеся лица были более привлекательными, о чем свидетельствует положительная корреляция между соответствующими оценками. Этот вывод не согласуется с исследованием, показывающим, что фактическая запоминаемость лиц отрицательно коррелирует с привлекательностью до такой степени, что предсказания запоминаемости верны. Наконец, знакомые лица считались более привлекательными, что согласуется с ранее сделанными выводами о том, что для человека куда приятнее обычное (не модельное) лицо.
Атрибут «снаружи» (независимо от того, было ли фото сделано в помещении или под открытым небом) был включен в анализ для оценки возможных путаниц при использовании натуралистичных фотографий лиц. Было обнаружено, что этот атрибут наименее коррелирует с другими атрибутами, показывая наименьшую максимальную абсолютную корреляцию для каждого атрибута (например, снаружи-доверительный r = 0.20).
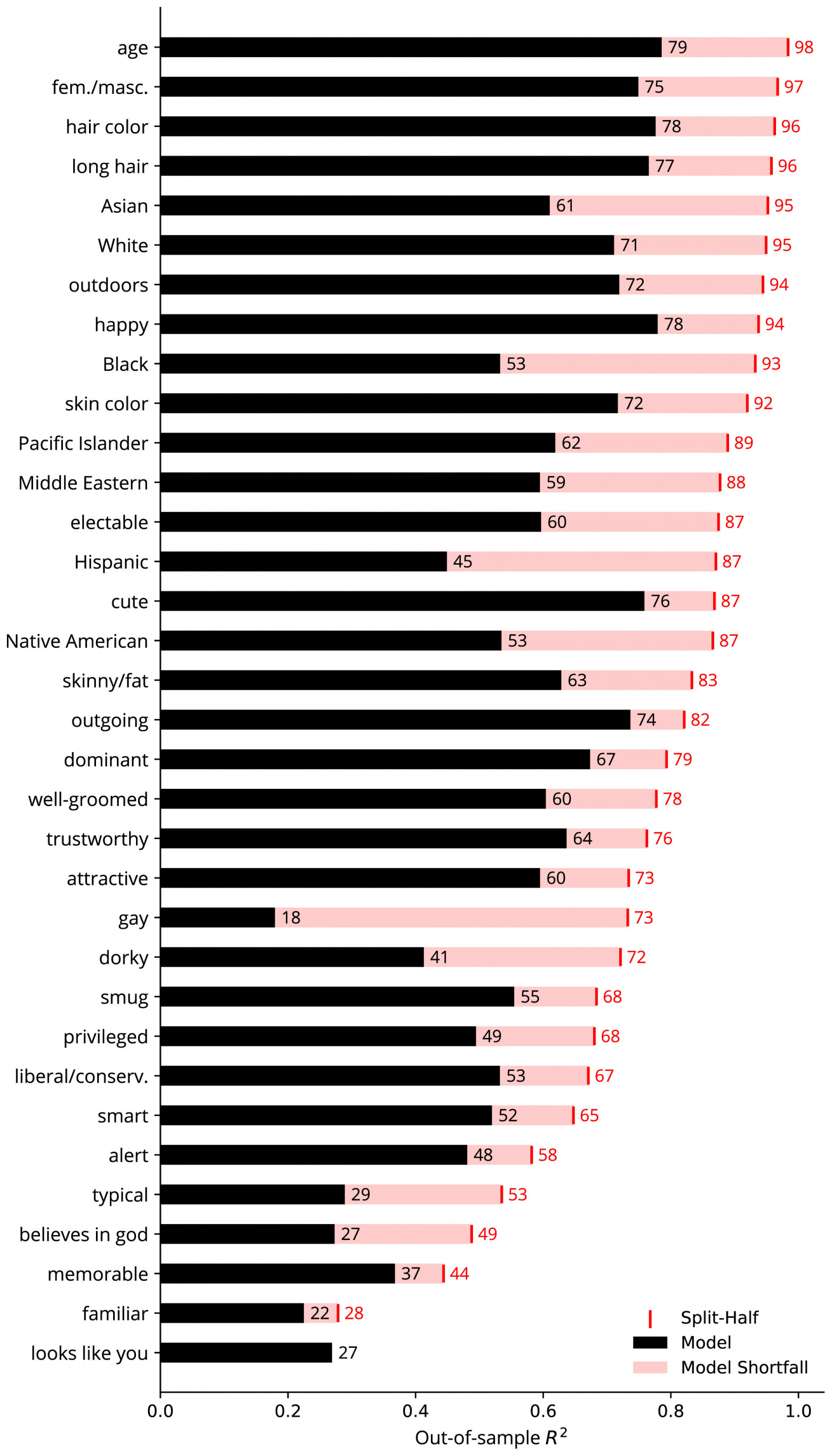
Для сравнения, атрибутом со следующим самым низким максимумом был худой/толстый (худой/толстый-привлекательный, r = 0.43), который, несмотря на удвоение величины, был одним из атрибутов, которые легче предсказать (изображение №2). Кроме того, факт того, что «снаружи» имел самую низкую корреляцию со всеми другими атрибутами (r = 0.08), указывает на минимальный вклад контекстуальных эффектов из-за естественного фона и освещения.
Прогнозирование атрибутивных выводов
Чтобы смоделировать атрибут, необходимо было начать с многомерных векторов представления zi = {z1,... zd}, назначенных каждому синтетическому лицу (i) в наборе стимулов с помощью предварительно обученной современной GAN* (от generative adversarial network).
GAN* (генеративно-состязательная сеть) — алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых (сеть G) генерирует образцы, а другая (сеть D) старается отличить правильные («подлинные») образцы от неправильных.
GAN изучила сопоставление каждого такого вектора с изображением посредством обширного обучения на большой базе данных фотографий реальных, несинтетических лиц. Затем выполнялось моделирование каждого психологического атрибута, измеренного с помощью средних оценок (yi), как линейной комбинации характеристик: yi = w0 + w1z1 +… + wdzd. Вектор весов wk = {w1,... wd} представляет атрибут как линейное измерение, пересекающее репрезентативное пространство, и настроен использованием перекрестной проверки.
Стоит отметить, что участники опроса частично расходятся в своих оценках суждениях, из-за чего сложно сформулировать точный прогноз. Чтобы лучше понять потолок прогнозирования, налагаемый ограниченной межэкспертной надежностью, необходимо было рассчитать надежность для каждого атрибута методом половинного разбиения, усредняя квадрат корреляции между средними значениями 100 случайных разделений оценок для каждого изображения.
Любопытно, что модели «знакомый» и «похожий на тебя» продемонстрировали наименьшие разрывы между эффективностью и надежностью. Это свидетельствует о том, что их непредсказуемость не связана с плохим качеством модели или отсутствием полезных входных функций. Скорее кажется вероятным, что фамильярность в большей степени, чем другие атрибуты, основана как на общей концепции или опыте, так и на гораздо более широкой личной концепции или опыте; только первое можно предсказать для участников в совокупности.
Атрибуты, соответствующие некоторым расовым или этническим социальным категориям демонстрировали больший разрыв между надежностью и эффективностью модели, чем другие атрибуты. Одной из возможных причин этого разрыва является смещение выборки в генераторе стимулов.
Факторы, влияющие на эффективность прогнозирования
Дабы охарактеризовать факторы, влияющие на эффективность прогнозирования, было проведено исследование влияния количества оцениваемых лиц на эффективность прогнозирования (сверху на изображении №3).
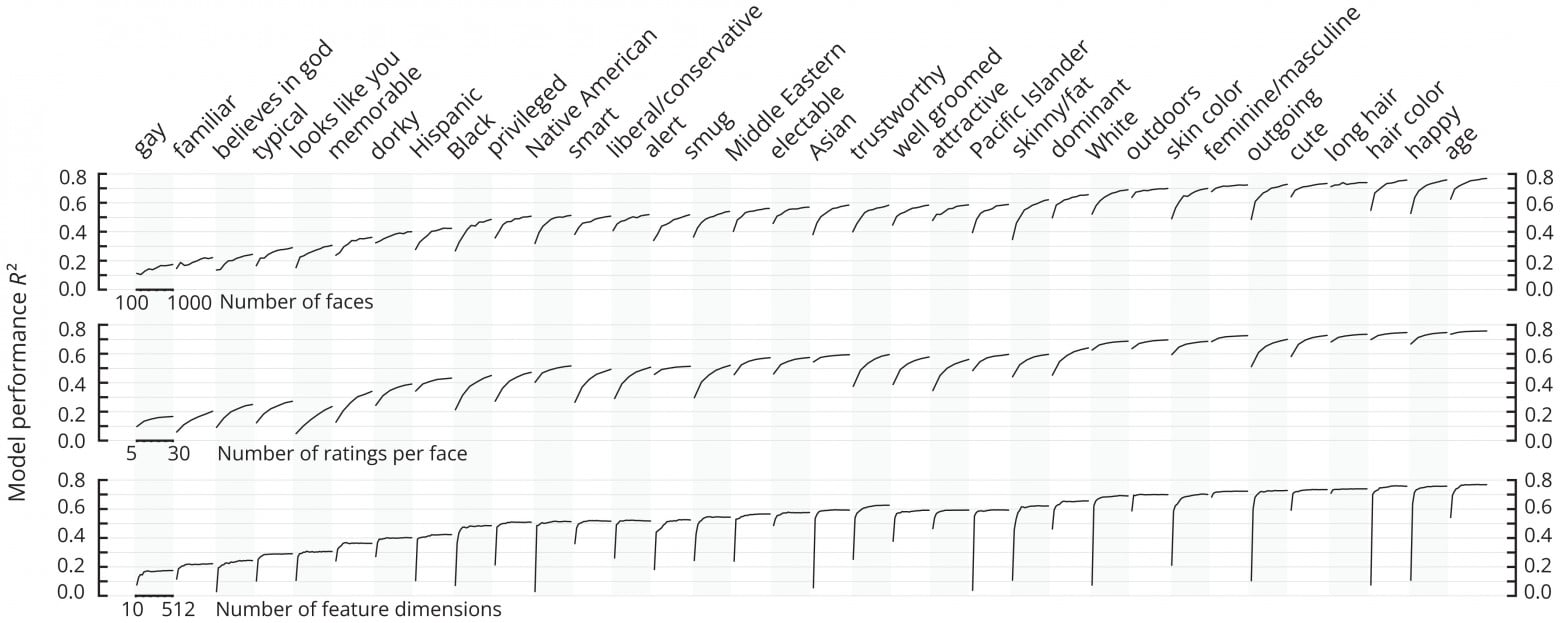
Кривые эффективности были созданы путем подгонки моделей для каждой из 30 случайных выборок изображений (от 100 до 1000 штук). Большинство атрибутов только выигрывали от увеличения количества оцениваемых лиц.
Затем ученые изучили взаимосвязь между количеством оценок, полученных от уникальных участников для каждого лица, и прогностической эффективностью (посередине на изображении №3). Кривые эффективности были созданы путем подгонки моделей к наборам данных с уменьшенной выборкой (от 5 до 30). Прирост эффективности за счет количества оценок уменьшался с увеличением количества уникальных оценок, но медленнее, чем прирост за счет количества лиц.
Наконец, была исследована взаимосвязь между количеством внешних признаков (всего 512) и эффективностью прогнозирования (внизу на изображении №3). Кривые эффективности создавались путем подгонки моделей с использованием сокращенных наборов признаков, полученных с помощью анализа основных компонентов (от 10 до 512).
В большинстве случаев наблюдалось быстрое насыщение эффективности, но в некоторых было незначительное улучшение при увеличении количества признаков. Оценка различных профилей насыщения показала, что 10 признаков вполне достаточно для удовлетворительного уровня эффективности прогнозирования. При этом увеличение числа признаков только способствует увеличению этого уровня.
Манипулирование атрибутивными выводами
Поскольку изученные векторы атрибутов соответствуют линейным размерам, существует возможность манипулировать произвольным лицом, представленным признаками zi, относительно атрибута k, используя векторную арифметику: zi + βwk, где β — скаляр, управляющий положительной или отрицательной модуляцией атрибутов.
Был применен симметричный диапазон β около 0 к каждому вектору атрибутов, чтобы манипулировать рядом представлений лиц как в отрицательном, так и в положительном направлениях, и декодировать результаты для визуализации с использованием того же компонента декодера/генератора нейронной сети, который использовался для получения представления.

Результаты вышеописанных преобразований показаны на изображении выше. Все манипуляции были поразительно плавными и эффективными по отношению к каждому параметру атрибута. К примеру, в аспекте атрибута «доверительный» манипулирование изменяло взгляд, улыбку, форму и женственность лица. Если же была задача увеличить атрибут «интеллект», то алгоритм старался добавлять к лицу очки и менять выражения лица в целом.
Стоит отметить, что манипуляции с выводом атрибутов могут влиять как на внутренние черты лица, так и на внешние черты. Когда изменяются только внутренние элементы лица, это происходит не потому, что GAN манипулирует только внутренними элементами, а потому, что внешние элементы ортогональны или не имеют отношения к этому выводу атрибутов в области обрабатываемого лица.
В заключение своего исследования ученые поставили интересный вопрос — надежно ли сгенерированные выше атрибутивные модели меняют представления участников об трансформированных лицах? Чтобы ответить на него, ученые провели серию экспериментов с участием 1000 человек.
В каждом из экспериментов один из двух типов лица (искусственное или реальное) сочетался с одним из 10 различных атрибутивных измерений, выбранных для представления широкого спектра различных моделей и уровней объективности/субъективности (возраст, женственность/мужественность, худой/толстый, доверительный, привлекательный, доминантный, умный, общительный, запоминающийся и знакомый). Как и в экспериментах по моделированию атрибутов, для экспериментов с искусственными лицами было случайным образом сгенерировано 50 уникальных синтетических лиц. В каждом испытании участникам показывали одно лицо и просили оценить его.
Каждое из показанных участникам лиц проходило несколько этапов манипулирования атрибутами, чтобы выдавать в результате три уровня выраженности того или иного атрибута. Если преобразование модели атрибутов действительно меняет суждение наблюдателя о лице, то в процессе экспериментов должны быть заметны изменения оценки со стороны участников.
Анализ результатов опытов показал, что манипуляции атрибутами действительно меняют представление участников о том или ином лице. При этом наблюдалась линейная тенденция в связи с увеличением уровня манипулирования тем или иным атрибутом. Следовательно, лицо, предположительно характеризующееся как «надежный/доверительный» можно было путем манипулирования атрибутов преобразовать в «ненадежный» и наоборот.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
В рассмотренном нами сегодня труде ученые продемонстрировали созданный ими алгоритм, который был обучен моделировать оценочные суждения человека в ответ на демонстрацию лиц. Данный алгоритм должен был предсказывать, как человек характеризует другого человека по чертам (атрибутам) его лица.
На этапе подготовки были использованы данные, полученные от более 1000 людей, которых попросили посмотреть на фото лиц и оценить. В результате лицам (а точнее их владельцам) приписывались различные характеристики: возраст, телосложение, интеллект, степень доверительности, степень привлекательности и т. д.
Полученные данные использовались для обучения нейронной сети GAN, которая в последствии могла имитировать оценочные суждения реальных людей. В результате полученный алгоритм мог самостоятельно оценивать и приписывать те или иные характеристики лицам.
Куда интереснее оказалось то, что изменение определенных параметров (атрибутов) лица с помощью данного алгоритма может кардинально поменять его оценку. К примеру, лицо, которое не вызывает доверия, с помощью алгоритма чудесным образом превращается в лицо человека, которому вы готовы доверить ключи от квартиры.
Разработчики осознают опасность такого функционала. Они сами заявляют, что манипулирование атрибутами лица можно применять, к примеру, в предвыборных гонках, делая лицо одного кандидата более доверительным, а лицо конкурента более отталкивающим. Потому ученые сразу же оформили патент на свою разработку и начали процесс создания компании для лицензирования алгоритма в заранее одобренных этических целях.
Несмотря на опасения касательно вредоносности такой технологии, ученые намерены продолжить над ней работать. В будущем они надеются усовершенствовать алгоритм, чтобы он мог точно предсказывать оценочные суждения конкретного человека в ответ на демонстрацию конкретных лиц.